Architecture
System Design
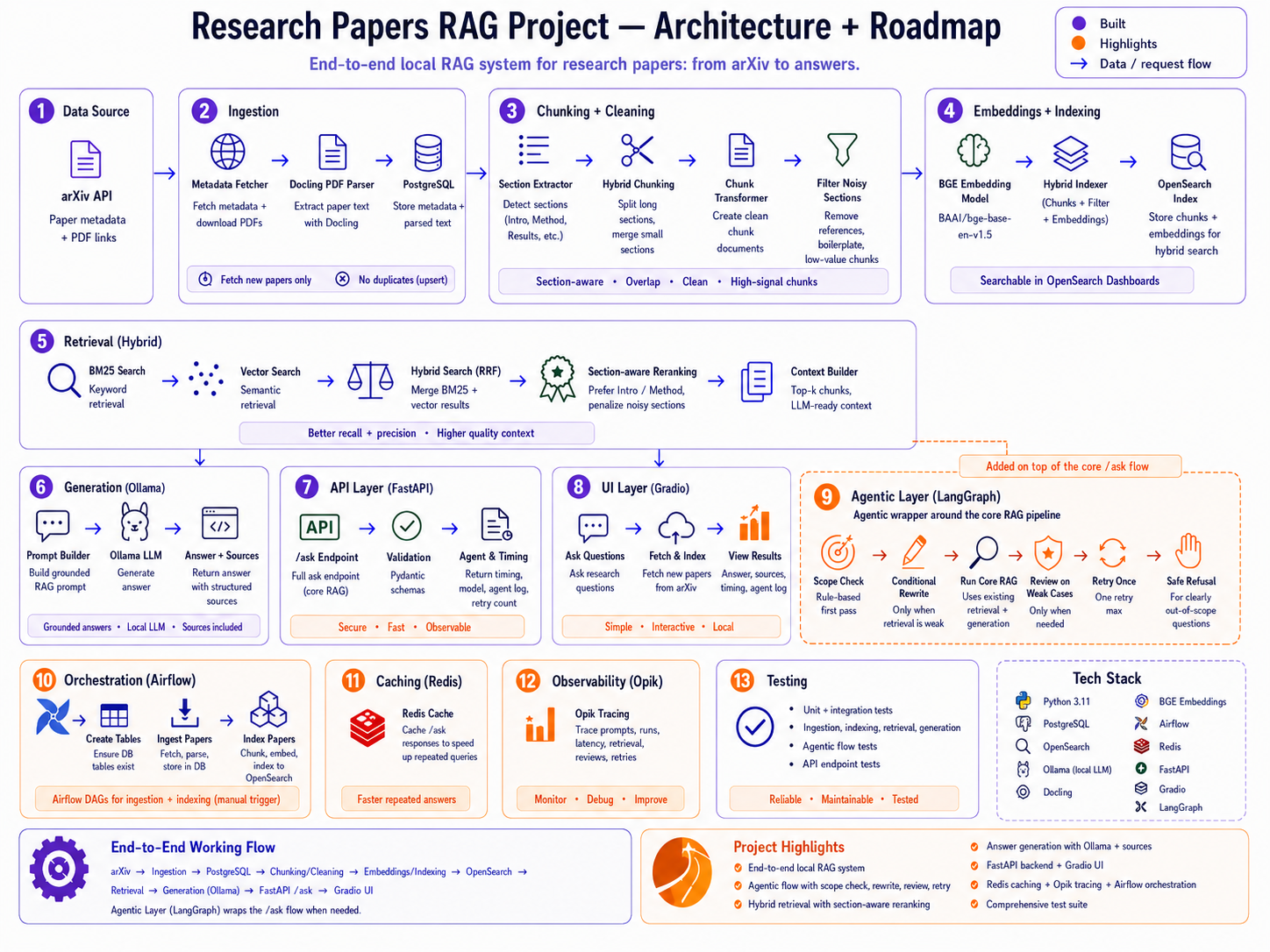
13-layer system from ingestion to hybrid retrieval to local generation, agentic control, caching, orchestration, and observability.
End-to-end local RAG system for research papers. From arXiv to answers. Inspired by Jam with AI by Shantanu Ladhwe & Shirin Khosravi Jam
Overview
This project is a fully local research-paper RAG system. The pipeline starts with arXiv metadata and PDF fetching, moves through Docling-based parsing and PostgreSQL storage, then prepares section-aware chunks for OpenSearch using BGE embeddings.
Retrieval combines keyword and semantic signals, while the answer layer uses Ollama locally through FastAPI and a Gradio interface. On top of that core flow, a LangGraph layer handles scope checks, conditional rewrites, weak-answer review, one retry, and safe refusal.
Why it matters
The value is not just that it answers questions from papers. The stronger part is the system thinking around it: handling noisy documents, improving retrieval quality, rejecting bad matches, tracing latency, caching repeated requests, and shaping the full stack into something that behaves more like a product than a notebook demo.
This project shows end-to-end ownership across data ingestion, search, LLM application design, agentic workflows, API design, UI integration, caching, orchestration, observability, and testing.
Architecture
13-layer system from ingestion to hybrid retrieval to local generation, agentic control, caching, orchestration, and observability.
Scope
arXiv API to Docling PDF parser to PostgreSQL storage to section-aware chunking to BGE embeddings to hybrid OpenSearch index.
BM25 + vector search + reciprocal-rank style fusion + section-aware reranking to improve recall while reducing noisy chunks.
LangGraph wrapper around the core /ask flow with scope check, conditional query rewrite, weak-answer review, one retry, and safe refusal for irrelevant questions.
FastAPI backend, Gradio interface, fetch-and-index flow from the UI, structured answer sources, timing logs, and agent logs.
Redis caching, Airflow DAGs for ingestion/indexing, Opik tracing for prompts and latency, and tests across retrieval, API, and agentic flow.
Engineering Decisions
Noisy chunks hurting retrieval quality
Built a chunk transformer and filtering step to remove references, repeated headers, boilerplate, and other low-signal sections before indexing.
Weak matches leading to bad answers
Added a weak-match gate before generation so the system can stop early instead of forcing a low-quality answer from weak retrieval.
Questions outside the project domain
Added an agentic scope check and safe refusal path so clearly irrelevant questions are rejected quickly instead of wasting retrieval and generation time.
Broad acronym-heavy questions like RAG, MCP, and LLM
Added conditional query rewriting and a review-and-retry step so the system can reformulate weak searches and recover from misleading first passes.
Repeated queries hitting the local LLM again and again
Added Redis caching on /ask responses so repeated questions return much faster without rerunning the full pipeline.
Technologies
Core App
Retrieval + ML
Ops + Workflow
Full docs, DAGs, tests, and local app flow included.